Retrieval Augmented Generation (RAG) Failure Modes in AI Systems & How to Fix Them in Production
Calibraint
Author
February 23, 2026
The enterprise race to deploy generative intelligence has entered a new phase. The era of experimentation has closed. Executive teams now expect measurable precision, auditability, and operational stability. A conversational interface is not enough. Systems must deliver answers grounded in verified data, aligned with internal policy, and defensible under scrutiny.
This shift explains why Retrieval Augmented Generation (RAG) has become the foundational architecture within serious AI development programs. Retrieval Augmented Generation connects large language models to enterprise knowledge repositories, reducing dependence on pretraining alone. It promises contextual intelligence anchored in proprietary data.
Yet the move from pilot to production reveals a deeper reality. Retrieval Augmented Generation succeeds in controlled demonstrations. In live environments, subtle structural weaknesses emerge. These weaknesses do not appear as system crashes. They surface as inconsistent answers, partial truths, or confident inaccuracies. Over time, trust erodes.
Understanding retrieval augmented generation failure modes in production is a prerequisite for building AI systems that influence decisions at scale.
Retrieval Augmented Generation and the Architecture of Trust
At its core, retrieval augmented generation inserts a retrieval layer between the user and the language model. Instead of relying solely on pretraining, the system searches a curated knowledge base, selects relevant documents, and supplies them as context for generation.
In theory, this creates grounded responses. In practice, each stage introduces potential distortion.
Trust in retrieval augmented generation depends on three structural pillars:
Accurate retrieval
Context integrity
Faithful generation
When any pillar weakens, the entire system becomes unreliable.
Executives often focus on model selection. In production environments, reliability depends far more on retrieval logic, data segmentation, and evaluation discipline.
Why RAG Breaks in Production
A RAG system is a pipeline, and like any pipeline, its reliability depends entirely on what happens at each handoff. Raw documents enter the system, get chunked into segments, converted into vector embeddings, and stored in a database. When a user submits a query, the system retrieves the most relevant chunks and passes them to the language model alongside the question. On paper, it is a clean, logical sequence. In production, each one of those handoffs is a potential failure point.
When retrieval pulls the wrong documents, the model never sees the information it needs. When chunking splits context at the wrong boundary, meaning arrives fragmented, and the model reasons from an incomplete picture. When re-ranking is absent or weak, the most relevant document gets buried under noise, and the model defaults to whatever sits highest in the prompt. And when the model itself is poorly constrained, it will often trust its own pre-trained patterns over the context it was explicitly given.
What makes RAG failure modes in AI systems particularly difficult to manage is that none of these breakdowns announce themselves. The output still arrives formatted, confident, and professional. The error only surfaces downstream, after a decision has been made, a client has been briefed, or a report has gone to the board. Only downstream, when a decision has been made or a client has been briefed, does the error surface.
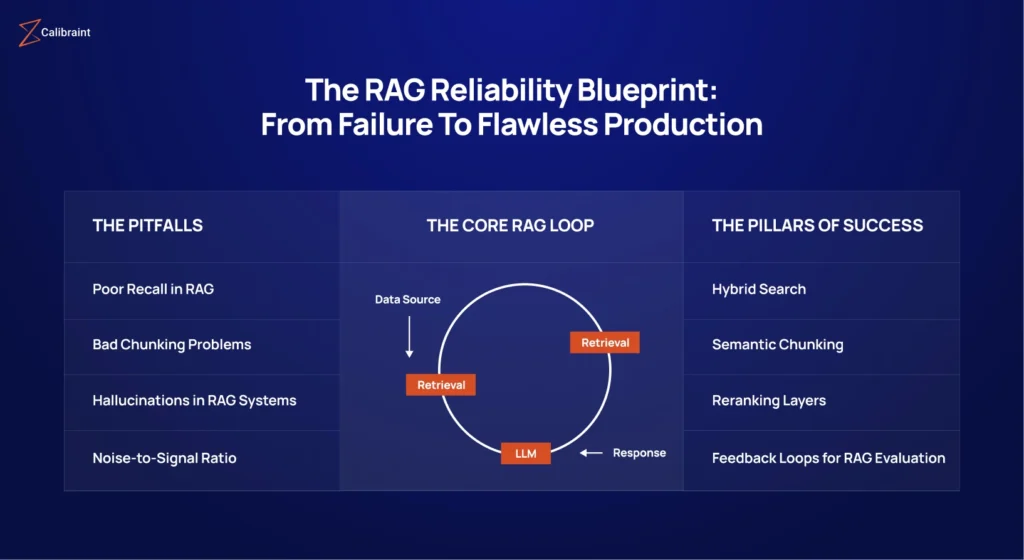
Failure Mode 1: Poor Recall in RAG
Poor recall in RAG is the most foundational failure. The system simply does not retrieve the document it needs. The model, receiving no relevant context, defaults to pattern-matching from its pre-training. The answer may sound reasonable. It is not grounded in your data.
This usually happens because vector search alone is insufficient for enterprise knowledge bases. Semantic embeddings are excellent at capturing conceptual similarity, but they underperform on specific identifiers: product codes, contract clauses, employee IDs, and regulatory references. A query about a specific clause number may return thematically related but legally distinct content.
The fix is a hybrid search. Combining dense vector retrieval with traditional keyword-based BM25 search captures both semantic meaning and lexical precision. Teams that implement hybrid search consistently report higher recall rates and fewer instances where the model fabricates answers due to missing context. Addressing poor recall in RAG at the infrastructure level is non-negotiable for any system handling regulated data or high-stakes decisions.
Failure Mode 2: Bad Chunking Problems
Chunking is how raw documents are divided before being stored in the vector database. It sounds like a minor implementation detail. In practice, bad chunking problems are responsible for a significant share of production failures.
Fixed-size chunking, the most common approach in quick implementations, splits text by character count regardless of meaning. A paragraph about a drug interaction might be split across two chunks. A legal clause might begin in one chunk and conclude in another. When the retrieval system pulls only half the context, the model receives an incomplete picture and generates an incomplete answer.
Chunking that is too large introduces the opposite problem. Oversized chunks dilute relevance and introduce irrelevant material into the prompt. The model may pull the right document but extract the wrong conclusion because the relevant sentence is buried in 800 words of surrounding context.
Semantic chunkingresolves bad chunking problems by splitting documents according to their natural structure: headings, sections, paragraphs, and logical breaks. The result is chunks that carry complete, self-contained ideas. Retrieval becomes more precise, and the model has what it actually needs to reason from.
Failure Mode 3: Hallucinations in RAG Systems
Hallucinations in RAG systems are the failure mode that worries executives most. The system retrieved the right document. The context was present in the prompt. And yet the model generated a response that contradicts it.
This happens because large language models are not simple lookup machines. They carry strong priors from pre-training, and under certain conditions, those priors override what they were explicitly given. If the retrieved context is ambiguous, fragmented, or competing with similar patterns in training data, the model may smooth over the gap with a fabrication that reads as confident.
Addressing hallucinations in RAG systems requires working at multiple layers. Reranking models, which score retrieved documents for relevance before they reach the generation step, reduce the chance of weak context reaching the prompt. Retrieval-grounded prompting instructions, which explicitly direct the model to answer only from the provided context and signal uncertainty when that context is insufficient, add a behavioral constraint that meaningfully reduces hallucination rates.
Monitoring also matters. Teams that track faithfulness scores, which measure whether the model’s answer can be directly traced to retrieved content, catch hallucinations in RAG systems before they compound into a pattern.
Failure Mode 4: System Drift
A RAG system that performed well at launch can degrade over months without a single code change. Data in the knowledge base becomes stale. Query patterns shift as users and business needs evolve. The index falls out of sync with current documents. The system begins returning answers that were accurate six months ago.
This is system drift, and it is the most overlooked of all RAG failure modes in AI systems. It does not trigger an error. It does not alert an engineer. It simply erodes the quality of outputs until someone notices that the AI is consistently behind.
Feedback loops for RAG evaluationare the structural answer to drift. These loops combine automated scoring, using metrics like faithfulness and answer relevancy, with periodic human review against a maintained ground truth dataset. Every update to the system is tested against this dataset. Every regression is caught before it reaches users.
Feedback loops for RAG evaluation should not be treated as a post-launch concern. They belong in the architecture from the beginning.
Most organizations do not fail at RAG because they chose the wrong model. They fail because they underinvest in the retrieval and evaluation infrastructure around it. The model is the last mile. Everything before it determines whether that last mile delivers value or risk.
A well-engineered production RAG system has five non-negotiable layers: hybrid retrieval that combines vector and keyword search, semantic chunking that respects document structure, a re-ranking model that filters for relevance before generation, retrieval-grounded prompting that constrains the model to context, and feedback loops for RAG evaluation that catch drift and degradation continuously.
Each layer addresses a specific category of RAG failure modes in AI systems. None of them is optional for enterprise deployments.
This is also where the AI development strategy diverges from AI experimentation. Building these layers requires deliberate architectural decisions, not just model selection. It requires engineers who understand retrieval theory, data pipeline design, and evaluation methodology, not just prompt engineering.
What This Means for Decision-Makers
If your organization is evaluating a RAG deployment or diagnosing an underperforming one, the questions to ask are specific. Where does your retrieval fall short? Is the index current? Are your chunks carrying complete context? Is the model faithfully grounding its answers in what was retrieved? Do your feedback loops for RAG evaluation run continuously or only at launch?
The answers to those questions determine whether your AI system is an asset or a liability. A system with strong retrieval, clean chunking, active reranking, and continuous evaluation is not just more accurate. It is more defensible, more auditable, and more trusted by the people who use it every day.
The difference between a RAG system that impresses in a demo and one that holds up under enterprise scrutiny is entirely in the engineering.
RAG failure modes in production do not disappear on their own. They require deliberate, layered solutions and a team that treats data quality and evaluation with the same rigor as model performance.
The next evolution in Retrieval Augmented Generation is already in early production for leading AI teams. Agentic RAG systems do not just retrieve and generate once. They reason about whether the retrieved information is sufficient, decide if additional retrieval steps are needed, and iteratively refine before producing a final answer.
This architecture raises the ceiling on what AI systems can do. It also raises the stakes on getting the foundation right. Every failure mode described in this guide becomes more consequential when the system is making multi-step decisions rather than answering a single question. The teams that invest now in eliminating RAG failure modes in AI systems are the ones who will be ready to deploy the next generation without rebuilding from scratch.
Is Your RAG Architecture Built to Hold?
If your RAG system is hallucinating, retrieving the wrong documents, or quietly drifting from your business reality, the problem is architectural, and it is fixable. Calibraint’s AI engineering team has diagnosed and rebuilt RAG pipelines across industries where accuracy is not optional. From hybrid retrieval design to continuous evaluation infrastructure, we build systems that hold up under real enterprise conditions.
If your current system is producing results you cannot fully trust, that is the signal. Start with an architecture audit at calibraint.com and find out exactly where your pipeline is failing and what it will take to fix it.
FAQs
1. What are the failure modes of RAG?
RAG failure modes include poor recall, bad chunking that breaks context, hallucinations from incomplete or conflicting data, noise-to-signal dilution as corpora grow, and insufficient feedback loops that prevent early detection of errors.
2. What is the main limitation of RAG retrieval augmented generation systems?
The main limitation is that RAG relies on retrieval quality; if relevant documents are missed, fragmented, or misranked, even the most advanced model will produce inaccurate or misleading responses.
3. Why do RAG applications fail in production?
RAG applications fail in production due to scaling challenges, evolving corpora, misaligned retrieval and generation, weak evaluation frameworks, and structural issues like poor chunking or inadequate feedback loops that are not visible in pilot tests.
Calibraint
Author
February 23, 2026
Let's Start A Conversation
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.